In SQL Server’s Always On Availability Groups, understanding the behavior of statistics on secondary replicas is key to maintaining query performance. This post explores the challenges and solutions for managing statistics in read-only secondary databases and snapshots. We delve into two critical scenarios: the creation of statistics in secondary replicas when they are missing on the primary, and the handling of stale statistics due to differences in primary and secondary workloads.
The secondary replica is a strict copy of primary the primarydatabase. So, the stats are created in tempdb linked with the readonly database. SQL server will maintain statistics of read-only secondary databases in tempdb. Your secondary workload (readonly) will be different from the primary workload (will be mostly writes (more) and reads).
Any statistics that are created on the primary replica is automatically available on the secondary replicas, however the queries that you will run on the secondary replica are, in all likelihood, very different than the ones you run on the primary replica. For this reason, the statistics may either be missing or possibly stale when a query is run on the secondary replica.
To overcome the performance problems that might result from missing or stale stats. Lets review the following scenerios:
Example-1: Missing statistics: Key scenario here is that you execute a query on the secondary replica that requires statistics on a column but the statistics are missing because the same query or any other query that requires the statistics on the same column was never run on the primary replica.
create table T1 (c1 int, c2 int, c3 int)
go
— insert into T1 1 row
insert into T1 values (-1, -1, -1)
— query T1 and show that stats got created automatically on T1/c1
select * from T1 where c1 = 1
— check the stats on table T1
select * from sys.stats where OBJECT_ID = object_id(‘T1’)
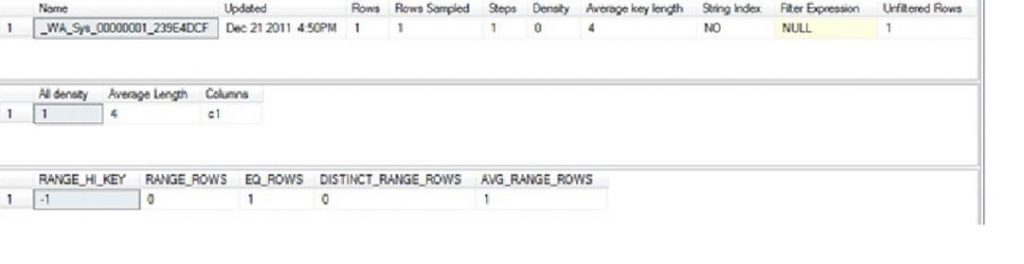
Here is the output. Note, that it shows that statistics was created automatically on table with object_id as 59757167 which happen to represent table ‘T1’. Other interesting thing to note here is that there is a new column ‘is_temporary’ representing that this statistics is permanent implying that it was created on the primary replica. This statistics will survive the failover (assuming no data-loss) and restart.

If you query sys.stats table on the secondary replica, you will see the same results because any logged operation is automatically available on the secondary replica. If you want to know more details, you can execute the following:
dbcc show_statistics(‘t1’, ‘c1’)
The output shows the row count, column on which the statistics is available along with other information.
Now, let us execute the following query on the secondary replica and check the statistics:
— query on column C2 to show TEMPSTATS
select * from t1 where c2= -1
–show the stats on the secondary
select * from sys.stats WHERE OBJECT_ID = OBJECT_ID(‘t1’)
Here is the output. Note, a new temporary statistic got created with the name ‘_WA_Sys_00000002_239E4DCF_readonly_database_statistics’ with the ‘is_temporary’ flag indicating that it is temporary. The statistics was automatically created because the optimizer needed it. The name of the statistics is appended with the suffix ‘_readonly_database_statistics’. This is done so that this name does not clash with other automatically created statistics on the primary replica. SQL Server 2012 prevents creating any statistics with this suffix. There is an outside chance that a permanent statistics already exists with this name (assuming someone explicitly created a statistics with this name) before database was upgraded to SQL2012. In that case, the temporary statistics creation will fail but your query will still succeed but the optimizer will not have the statistics as needed for optimization.

The temporary statistics are stored in TempDB and each statistics typically takes 8K (1 page) of storage. You can always query sys.stats table to find out all temporary statistics and estimate the storage space taken in the temporary database. Other point to note is that statistics created as part of auto-stats use data sampling so the creation of these statistics is fast and does not depend on the size of the table. One drawback is that if the data for the column is skewed then the statistics based on the sampled data are not very accurate. In such cases, if you want, you can create the statistics on the primary replica without sampling and then it will be available on the secondary replica. The temporary statistics are lost when the secondary replica is either restarted or when primary replica fails over.
Example-2: Stale Statistics: Key scenario is that the statistics on a column was either explicitly or automatically created but has become stale due to DML operations. The statistics stay stale because there was no query run on the primary that required this statistics since the last update. Now, if we run a query on the secondary replica, this statistics will get updated automatically so that the optimizer can use it for optimization. Let us take the previous example where we have a table T1 with 1 row and permanent statistics on column C1 and temporary statistics on C2.
— insert 10000 rows on the primary to make the statistics stale
declare @i int = 0
while (@i < 10000)
begin
insert into t1 values (@i, @i + 1000, @i + 10000)
set @i = @i + 1
end
Now, we execute the following query on the secondary
— Query on the secondary so that stats are updated with TEMPSTATS
select c2 from t1 where c1 = 100
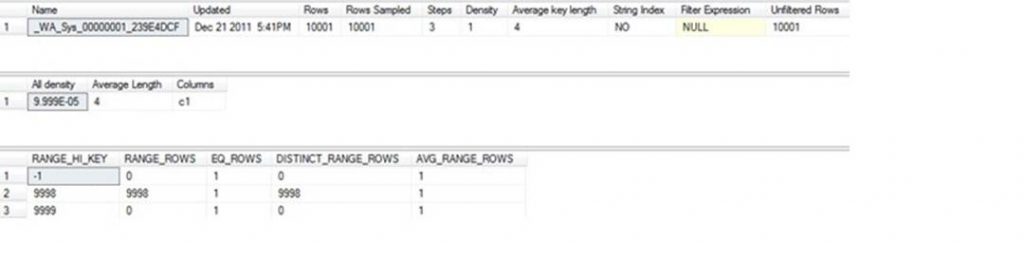
Here is the output of the statistics. Note that the statistics ‘_WA_Sys_00000001_239E4DCF’ got updated and is now marked as ‘is_temporary’ being 1. This implies that SQL Server has created a temporary statistics. This does not mean that the permanent statistics got lost. It is still available but SQL Server knows that there is an updated version on this statistics in TempDB and it will use that.

Let us see the full details of this statistics
dbcc show_statistics(‘t1’, ‘_WA_Sys_00000001_239E4DCF’)
The output is as follows showing that there are now 10001 rows and this statistics in on column C1
If you restart your secondary replica, the temporary statistics will be lost and you will see the following output. In fact, if you query the statistics on the primary, you will see the same output as well.

You may wonder what happens if the statistics on C1 get updated on the primary replica. Let us repeat this experiment by running the following query on the primary
— query t1 and show that stats got created created automatically on t1/c1
select * from t1 where c1 > 1000
This query will cause the statistics on column C1 to get updated and when it flows to secondary replica, the statistics will be marked as permanent and now the optimizer will use the permanent statistics as it is the latest statistics available on column C1.
In summary, to illustrate various interactions, let us take a table T1 with three columns C1, C2, and C3. For this discussion, it does not matter what the column type is. We will use C1prim and C1sec to represent statistics on column C1 that got created on primary and secondary replica respectively
The following table summarizes various interactions
| Action | Primary Replica | Secondary Replica |
| Query on Secondary with predicate on C1 | C1sec gets created | |
| Query on Primary with predicate on C1 | C1prim gets created | C1prim is created on when the log for the statistics is processed. At this time, both C1sec and C1prim exist on secondary replica but the C1prim is latest and optimizer will use it. At this time C1sec is not useful and user can explicitly drop it. |
| Memory pressure forces T1 out of cache | C1sec is removed from the cache but it still persists in TempDB | |
| Insert bunch of rows in T1 such that auto-stat threshold is crossed. Now query on the secondary with predicate on C1 | C1sec gets refreshed. | |
| Query on Primary with predicate on C2 | C2prim gets created | C2prim is created on when the log for the statistics is processed. |
| Insert bunch of rows in T1 such that auto-stat threshold is crossed. Now query on the secondary with predicate on C2 | C2sec gets created. At this time, both C2sec and C2prim exist on secondary replica but the C2sec is latest and optimizer will use it. | |
| Do a DDL operation on table T1 | Cached metadata for T1 is deleted and as part of it C1sec and C2sec gets dropped. |
The same mechanism works on read-only database and database snapshot.
Managing statistics in SQL Server Availability Groups is important for optimal query performance, especially in read-only secondary replicas. We highlighted the complexities of dealing with missing and stale statistics in such environments. We saw how SQL Server adeptly addresses these challenges by creating temporary statistics in tempdb and updating them as needed. These insights are invaluable for database professionals striving to ensure efficient and reliable query performance in high-availability SQL Server environments.