With its debut in SQL Server 2019, Accelerated Database Recovery (ADR) represents a paradigm shift in database recovery and performance enhancement. The primary objective of ADR is to drastically cut down the time databases require to recover from crashes, failures, or restarts. This is particularly important in environments where long-running transactions are common, ensuring that databases remain available and performant, even in the face of unexpected disruptions.
Key Components of Accelerated Database Recovery
- Persistent Version Store (PVS): Unlike the traditional version store that is kept in the tempdb database, PVS is stored within the user database itself. This approach ensures that all the necessary information for recovery is contained within the database, eliminating the dependency on tempdb for storing row versions.
- Logical Revert: This feature allows the database to quickly revert a transaction by using the row versions stored in PVS, instead of physically rolling back the transaction. This process is significantly faster, especially for long-running transactions.
- S-Log Reuse: ADR allows for more aggressive truncation of the transaction log by ensuring that the log records are not needed for crash recovery, which is possible due to the efficient management of row versions in PVS.
Advantages of Accelerated Database Recovery
- Faster Database Recovery: Reduces the time it takes for a database to recover from a crash or restart, thereby increasing availability.
- Quick Transaction Rollback: Enables rapid rollback of transactions, regardless of their size or duration.
- Reduced Impact on Tempdb: By using PVS within the user database, ADR lessens the load on tempdb for version storage.
- Improved Truncation of Transaction Log: Helps in managing the size of the transaction log more effectively.
ADR Components

Persistent Version Store (PVS)
Unlike the traditional version store which resides in tempdb, the PVS is stored directly within the user database that it pertains to. This design choice ensures that versioning information is closely tied to the data it represents and is not lost in case of a system crash, thus speeding up the recovery process since the necessary information for any in-progress transactions is readily available within the database itself.
PVS is designed to be space-efficient, ensuring that the additional storage requirement within the user database does not become a significant burden
- Enables Resource Isolation
- Improves availability of readable secondaries
PVS: In-Row Versions
In-row storage means that the version information for a row is stored directly within the same data page as the original row itself. This approach is used when the versioned data is small enough to fit within the existing page structure without causing page overflows.
PVS: Off-Row Versions
Off-row storage is utilized when the version information for a row is too large to fit within the same data page as the original row. In such cases, the versioned data is stored in a separate page, potentially in a different part of the database file. A pointer or reference is then used to link the original row to its versioned information
PVS: Version Tracking & Cleanup
Version tracking in PVS involves keeping track of all the versions of each row that are created as a result of data modifications (inserts, updates, deletes) by transactions. This is crucial for several features, including:
- Transaction Rollback: Allows for the quick reversal of changes made by transactions that are not committed.
- Read Consistency: Ensures that queries can read a consistent view of the data, even if other concurrent transactions are modifying the same data.
- Recovery: Facilitates the database’s ability to recover to a consistent state quickly after a crash or restart.
To manage these row versions effectively, PVS stores metadata alongside the versioned rows. This metadata includes information such as the transaction ID that created the version, the sequence number of the version, and pointers for navigating the version chain for a particular row.
The cleanup process works continuously in the background, identifying and removing versions that are no longer necessary. This process is designed to minimize its impact on database performance, running at a lower priority than other database operations.
Logical Revert
Under traditional transaction rollback mechanisms, if a transaction needed to be reverted, the database would physically undo each operation performed by that transaction. This process could be time-consuming for large or long-running transactions, as the system would need to sequentially reverse each change made to the database.
Logical Revert, on the other hand, leverages the versioning information stored in the Persisted Version Store (PVS) to quickly restore the database to its state before the transaction began. Instead of sequentially undoing each operation, Logical Revert accesses the versioned rows in PVS that represent the state of the data prior to the transaction’s modifications. This approach allows the database to “jump back” to the previous state instantly, regardless of the transaction size or duration.
- Keeps track of all aborted transactions
- Performs rollback using PVS for all user transactions
- Releases all locks immediately after transaction abort
- Performs user transaction rollback asynchronously

sLog
The primary purpose of the S-Log mechanism is to enable more efficient log truncation and space reuse in the transaction log by changing how the database handles the information needed for recovery. Traditional transaction log management requires keeping all log records associated with open transactions because they might be needed for rollback or recovery. This requirement can lead to large transaction log growth, especially with long-running transactions.
- Low volume & in-memory
- Persisted on disk by been serialized during SQL Checkpoint
- Periodically truncated as transactions commit
- Accelerates Redo and Undo by processing only the non-versioned operations
- Enables aggressive transaction log truncation by preserving the required log records
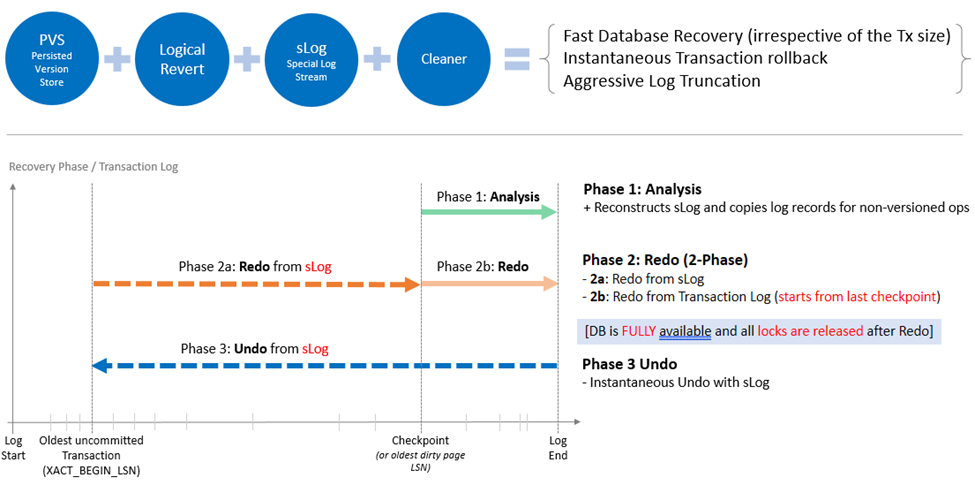
SQL Server Database Recovery (with ADR)
Impact of ADR on Always On Availability Groups
- Improved Recovery Times: One of the primary benefits of ADR is significantly reduced recovery times for databases. This improvement directly benefits Always On Availability Groups by decreasing the time it takes for a database in an availability group to recover after a failover or restart. Faster database recovery helps minimize downtime and ensures that applications can quickly reconnect to the database after a failover, enhancing the overall availability of the system.
- Reduced Impact of Long Transactions: ADR’s ability to quickly rollback transactions, regardless of their size or duration, means that long-running transactions have a reduced impact on database recovery processes. In the context of Always On Availability Groups, this capability can help prevent scenarios where a long transaction might delay the failover process or the synchronization between primary and secondary replicas.
- Transaction Log Management: ADR optimizes transaction log management through mechanisms like the S-Log. This optimization can lead to more efficient log truncation and space utilization, which is particularly beneficial for Always On environments where transaction log records are continuously replicated to secondary replicas. Efficient log management helps ensure that log growth is controlled and that the replication of log records to secondary replicas is as efficient as possible.
- Compatibility and Integration: ADR is designed to be fully compatible with Always On Availability Groups. It operates transparently, meaning that enabling ADR on databases that are part of an availability group does not require any additional configuration for the availability group itself. The benefits of ADR, such as improved recovery times and efficient transaction rollback, are automatically applied to the databases without affecting their replication or availability group configurations.
Impact of ADR on Replication: Enabling ADR on a database generally should not directly impact the functionality of replication. Replication is more concerned with the committed state of the data rather than the mechanisms used for recovery. Since ADR primarily affects how transactions are rolled back and how the database recovers from failures, its use should be transparent to replication processes. However, because ADR can significantly improve recovery times, it may indirectly benefit replication scenarios by ensuring that the primary database is available more quickly after a failure, thus reducing potential delays in replication due to database unavailability.
Impact of ADR on CDC: Since CDC operates at the transaction log level to capture changes, there might be concerns about whether ADR’s optimizations around log management and recovery could affect CDC operations. However, ADR is designed to be compatible with existing SQL Server features, including CDC. The logical handling of transactions and the improvements in log management introduced by ADR do not interfere with the ability of CDC to capture data changes. CDC continues to function normally, capturing changes from the transaction log as it would without ADR enabled.
SQL 2022 enhancements
Multi-threaded Version Cleanup
In SQL Server 2019 (15.x), the ADR cleanup process is single threaded within a SQL Server instance. Beginning with SQL Server 2022 (16.x), this process uses multi-threaded version cleanup (MTVC), that allows multiple databases under the same SQL Server instance to be cleaned in parallel.
MTVC is enabled by default in SQL Server 2022 and uses one thread per SQL instance. To adjust the number of threads for version cleanup, set ADR Cleaner Thread Count with sp_configure.
| USE master; GO — Enable show advanced option to see ADR Cleaner Thread Count EXEC sp_configure ‘show advanced option’, ‘1’; — List all advanced options RECONFIGURE; EXEC sp_configure; — The following example sets the ADR Cleaner Thread Count to 4 EXEC sp_configure ‘ADR Cleaner Thread Count’, ‘4’; RECONFIGURE WITH OVERRIDE; — Run RECONFIGURE to verify the number of threads allocated to ADR Version Cleaner. RECONFIGURE; EXEC sp_configure; |
User Transaction Cleanup
This improvement allows user transactions to run cleanup on pages that could not be addressed by the regular cleanup process due to lock conflicts. This helps ensure that the ADR cleanup process works more efficiently.
Reducing Memory Footprint for PVS Page Tracker
This improvement tracks persisted version store (PVS) pages at the extent level, in order to reduce the memory footprint needed to maintain versioned pages.
Accelerated Data Recovery Cleaner Improvements
ADR cleaner has improved version cleanup efficiencies to improve how SQL Server tracks and records aborted versions of a page leading to improvements in memory and capacity.
Transaction-level Persisted Version Store
This improvement allows ADR to clean up versions belonging to committed transactions independent of whether there are aborted transactions in the system. With this improvement PVS pages can be deallocated, even if the cleanup cannot complete a successful sweep to trim the aborted transaction map.
The result of this improvement is reduced PVS growth even if ADR cleanup is slow or fails.
Conclusion
Accelerated Database Recovery (ADR) represents a significant leap forward in database management technology, offering unparalleled improvements in recovery times, transaction rollback efficiency, and overall database availability. By integrating innovative components like PVS and Logical Revert, and continuously evolving with features like multi-threaded cleanup in SQL Server 2022, ADR not only addresses current challenges but also anticipates future demands. As databases become increasingly central to organizational success, ADR emerges as a key enabler of resilience, performance, and efficiency, marking a new era in the quest for robust and reliable database systems.