This is a brief walkthrough of the process required to setup change data tracking (CDC) to be HADR aware. When setting up CDC for a database, SQL Server will create two SQL Agent jobs to manage change tracking. The most critical of these is the capture job which needs to be running continuously to capture all changes to the target tables. This can be an issue if the database is in an availability group and a failover occurs.
Once a failover happens the CDC job on the original primary will fail because the database goes into read-only mode meaning CDC capture stops. We will walk through the required steps to configure the availability replicas to manage this properly and start the CDC job on the new primary after a failover has occurred. This will automate the process and eliminate the need for manual intervention after to a failover to ensure the CDC is working properly.
Follow the steps below to implement AG aware CDC SQL Agent jobs:
- Login to the primary replica using SQL Server Management Studio.
- If CDC is not yet enabled on the target database, use the following command to setup the database for CDC. Be sure to replace [mydb] with the name of the target database.
USE [mydb]
EXEC sys.sp_cdc_enable_db
GO- Now that CDC is enabled at the database level, we need to enable CDC on the specific tables we’d like to track. Use the following command to add a table and replace mytable with your table name:
EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'mytable',
@role_name = NULL,
@supports_net_changes = 1
GOFor a complete explanation of the above two TSQL statements please refer to the official Microsoft documentation link below:
Enable and Disable change data capture – SQL Server | Microsoft Learn
- The previous step created two SQL Agent jobs. An example can be seen below:

These two jobs need to be edited to make them AG aware. The capture job has two steps which need edited and the cleanup job has one step requiring modification. Each of these steps need the following TSQL placed at the beginning of each agent job step:
DECLARE @DatabaseName SYSNAME = DB_NAME()
IF (SELECT sys.fn_hadr_is_primary_replica(@DatabaseName)) = 1
BEGIN
-- Insert the operations to be performed when the condition is true here
ENDThe following screenshot shows an example where step 2 of the capture job has been edited to be AG aware:
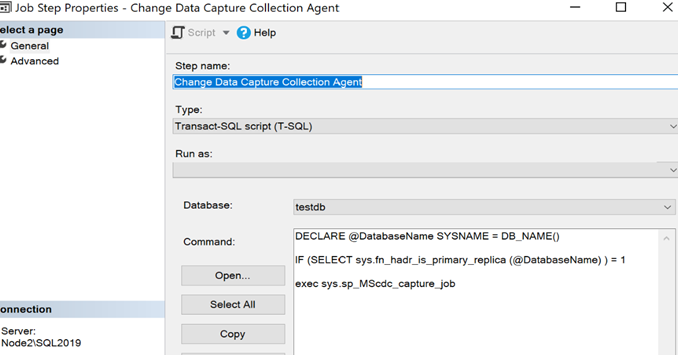
- We will next need to add another schedule to the capture job which attempts to start the job every minute. This is needed so that CDC begin capturing as soon as possible after a failover event. Below is an example of such a schedule being configured:
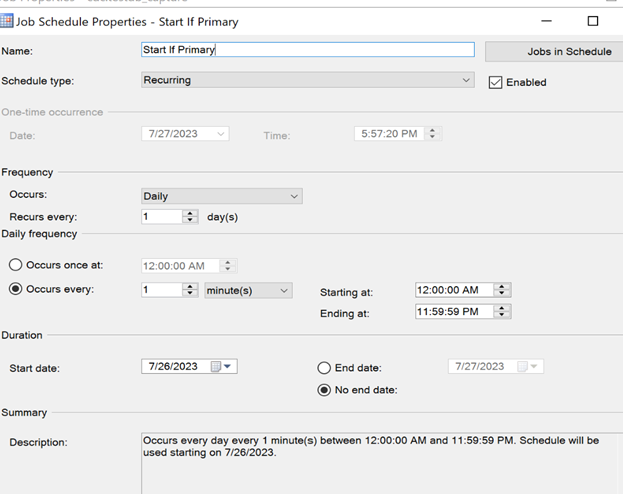
Once the new schedule is created, your schedules should look something like this:
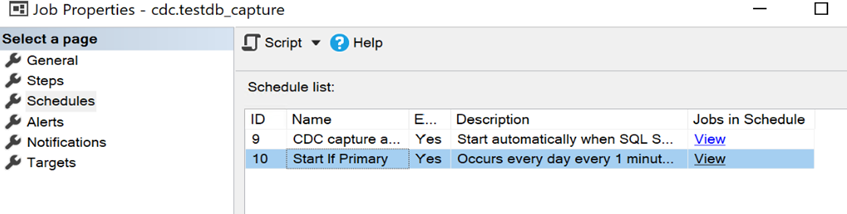
- You will now need to script out the two CDC jobs on the primary replica so we can recreate the jobs on the secondary replica. This can be done by expanding the SQL Server Agent node in Object Explorer and scripting out the job as seen in the screenshot below:
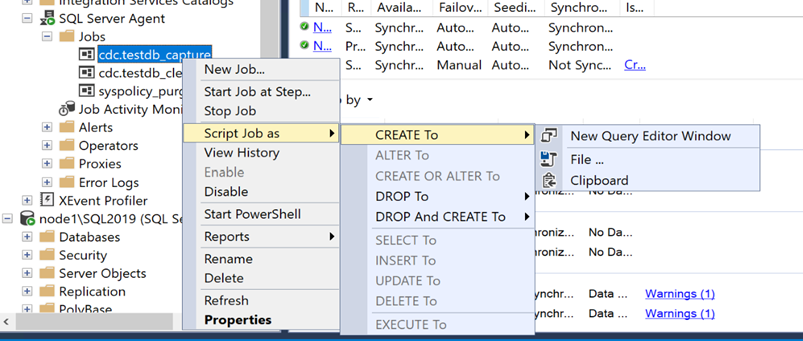
- Before we connect to the secondary replica we need to capture some SQL statements to populate the cdc_jobs table as seen in the screenshot below:
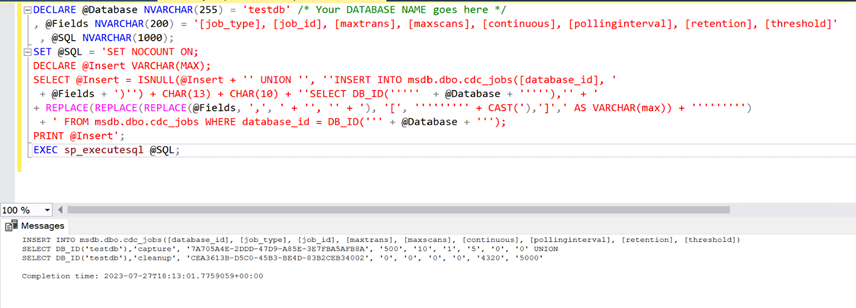
Copy the SQL statements generated under Messages and save them for later. We will use these statements to copy the contents of your cdc_jobs table in MSDB on the secondary replica. The following is the code snippet above that can be pasted into the editor:
DECLARE @Database NVARCHAR(255) = 'testdb' /* Your DATABASE NAME goes here */
, @Fields NVARCHAR(200) = '[job_type], [job_id], [maxtrans], [maxscans], [continuous], [pollinginterval], [retention], [threshold]'
, @SQL NVARCHAR(1000);
SET @SQL = 'SET NOCOUNT ON;
DECLARE @Insert VARCHAR(MAX);
SELECT @Insert = ISNULL(@Insert + '' UNION '', ''INSERT INTO msdb.dbo.cdc_jobs([database_id], '
+ @Fields + ')'') + CHAR(13) + CHAR(10) + ''SELECT DB_ID(''''' + @Database + '''''),'' + '
+ REPLACE(REPLACE(REPLACE(@Fields, '', '', '' + '', '' + ''), ''['', '''''''' + CAST(''), '']', ' AS VARCHAR(max)) + '''''''')
+ ' FROM msdb.dbo.cdc_jobs WHERE database_id = DB_ID(''' + @Database + ''');
PRINT @Insert';
EXEC sp_executesql @SQL;
- Connect to the secondary replica and run the following query to ensure CDC has been enabled on the secondary as well:
SELECT name, is_cdc_enabled FROM sys.databases;- Now we will recreate the cdc_jobs table in the MSDB database. The script to create this table can be found below:
CREATE TABLE [dbo].[cdc_jobs] (
[database_id] [int] NOT NULL,
[job_type] [nvarchar](20) NOT NULL,
[job_id] [uniqueidentifier] NULL,
[maxtrans] [int] NULL,
[maxscans] [int] NULL,
[continuous] [bit] NULL,
[pollinginterval] [bigint] NULL,
[retention] [bigint] NULL,
[threshold] [bigint] NULL,
PRIMARY KEY CLUSTERED (
[database_id] ASC,
[job_type] ASC
)
WITH (
PAD_INDEX = OFF,
STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF,
ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON
) ON [PRIMARY]
) ON [PRIMARY];
- Now that we have a cdc_jobs table created on the secondary, we will now need to populate it with the data captured from the primary in step 7. Execute the SQL statements captured against the MSDB database on the secondary. You may want to confirm that the cdc_jobs table on the secondary does indeed match the primary’s version. An example of a cdc_jobs table after the copy can be seen below:
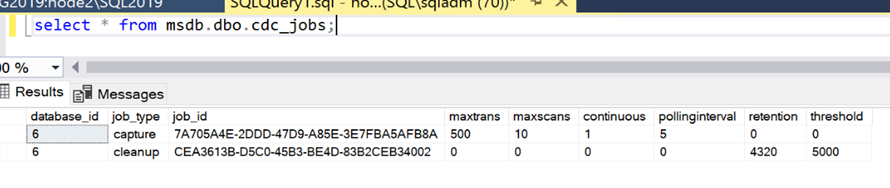
- How that we have updated the cdc_jobs table on the secondary replica, we need to create the cdc_jobs_view system view in the MSDB database which is required by the CDC SQL Agent Jobs:
CREATE VIEW dbo.cdc_jobs_view AS
SELECT
[database_id],
[job_type],
[job_id],
[maxtrans],
[maxscans],
[continuous],
[pollinginterval],
[retention],
[threshold]
FROM dbo.cdc_jobs;- Now that the SQL Agent jobs are created, we need to update the cdc_jobs table in MSDB to reflect the correct job IDs. Run the following script on the secondary replica to update cdc_jobs:
UPDATE c
SET c.job_id = s.job_id
FROM msdb.dbo.sysjobs s
JOIN msdb.dbo.cdc_jobs c ON s.name = 'cdc.' + DB_NAME(c.database_id) + '_' + c.job_type
WHERE DB_NAME(c.database_id) = 'testdb';
- Before we test the setup with a failover, be sure that all CDC jobs and job schedules are enabled. When a failover occurs, the agent job on the original primary will fail because the database goes into read-only mode. Within a minute of the failover, the new primary will execute its CDC capture job and it will proceed with change capture for the table.
In conclusion, setting up Change Data Capture (CDC) to be High Availability Disaster Recovery (HADR) aware is an essential step for ensuring data integrity and continuity in SQL Server environments. Through the detailed walkthrough provided, database administrators can effectively manage and automate CDC operations across primary and secondary replicas, thereby minimizing downtime and manual intervention in the event of failovers. By leveraging SQL Server Management Studio, specific T-SQL commands, and the Query Store, this setup not only enhances the resilience of your database system but also ensures that data changes are continuously captured, even in complex high availability scenarios. Implementing these steps will lead to a more robust and reliable database system, ready to handle the challenges of today’s data-driven environments.
Hello Yvonne,
Thanks for your post this is usefull to me. I am using SQL server 2019 version and I implemented the CDC on AG servers and i followed your post and setup the CDC, but When I failed over the AG from primary to Secondary all CDC jobs are failing and got below error.
. Invalid object name ‘msdb.dbo.cdc_jobs_view’. [SQLSTATE 42S02] (Error 208) The call to sp_MScdc_capture_job by the Capture Job for database ‘XXXXXX failed. Look at previous errors for the cause of the failure. [SQLSTATE 42000] (Error 22864). NOTE: The step was retried the requested number of times (10) without succeeding. The step failed.
Please provide the fix for this CDC jobs failing issue. I tried to get the msdb.dbo.cdc_jobs_view script and it wont allow me to get it.
in step 7 whatever you provided the script, that has some syntax errors compare to the screenshot.
Corrcted with your screenshot:
DECLARE @Database NVARCHAR(255) = ‘DPTRACK_STAGING’ /* Your DATABASE NAME goes here */
, @Fields NVARCHAR(200) = ‘[job_type], [job_id], [maxtrans], [maxscans], [continuous], [pollinginterval], [retention], [threshold]’
, @SQL NVARCHAR(1000);
SET @SQL = ‘SET NOCOUNT ON;
DECLARE @Insert VARCHAR(MAX);
SELECT @Insert = ISNULL(@Insert + ” UNION ”, ”INSERT INTO msdb.dbo.cdc_jobs([database_id], ‘
+ @Fields + ‘)”) + CHAR(13) + CHAR(10) + ”SELECT DB_ID(””’ + @Database + ””’),” + ‘
+ REPLACE(REPLACE(REPLACE(@Fields, ‘,’, ‘ + ”, ” + ‘), ‘[‘, ””””’ + CAST(‘), ‘]’, ‘ AS VARCHAR(max)) + ””””’)
+ ‘ FROM msdb.dbo.cdc_jobs WHERE database_id = DB_ID(”’ + @Database + ”’);
PRINT @Insert’;
EXEC sp_executesql @SQL;
Hi Raj, Thanks for bringing this to our attention. We accidentally omitted the step where the cdc_jobs_view object is created. We have now corrected the post. Please let us know if you encounter further issues.
The code is still invalid. Raj’s code works, but posting it online replaced the single quotes with special curly quotes or double curly quotes.
Just to say that databases can have different id’s on different nodes within an availability group. So you will need to check that when populating the data in the cdc_jobs table.