Introduction
In SQL Server, Availability Groups serve as a pivotal feature for ensuring database availability and disaster recovery. A fundamental aspect of managing Availability Groups is understanding how data synchronization occurs between the primary and secondary replicas within the group. This process ensures that all replicas are up-to-date, reflecting changes made in the primary database across all secondary databases in the group. Let’s look into how this synchronization works and the importance of the ‘redo’ operation in maintaining data consistency.
Synchronization Process: From Primary to Secondary Replicas
When changes are made to a database in the primary replica of an Availability Group, these modifications are promptly sent or synchronized to all secondary replicas defined within the same group. This is the first step in ensuring that all replicas maintain an up-to-date state of the database.
Upon the arrival of these changes at a secondary replica, they undergo a critical process before reflecting in the database files. Initially, these changes are written or ‘hardened’ to the transaction log file of the Availability Group database. This step is crucial as it ensures that the data is safely stored on disk before any further processing.
The Role of Redo in Recovery
Following the hardening process, SQL Server initiates a ‘recovery’ or ‘redo’ operation. This operation is vital for updating the database files with the changes that were recorded in the transaction log file. Essentially, the ‘redo’ operation is what brings the secondary database files in sync with the primary database, ensuring data consistency across the Availability Group.
Managing the Recovery Queue
It’s important to note that, at times, changes might be sent and hardened on the secondary replica’s transaction log file more rapidly than they can be processed by the ‘redo’ operation. When this happens, a recovery ‘queue’ is formed. This queue consists of all the hardened transaction log work that is pending recovery into the database. Managing this queue is crucial for maintaining the efficiency of data recovery and ensuring that the secondary replicas can quickly catch up with the primary replica.
Symptoms and Impact of Recovery (redo) Queueing
- Querying secondary returns different results than the primary replica: Read only workloads which query secondary replicas may query stale data. If there is recovery queuing, changes to data on the primary replica database are not yet reflected in the secondary database when querying the same data. For more information see the section Data latency on secondary replica.
- Failover Time is Longer / Recovery Time Objective (RTO) is violated: RTO is the maximum database downtime an organization can handle or how quickly the organization can regain access to the database after an outage. If substantial recovery queueing is present on a secondary replica and a failover occurs, recovery may take longer before the database will transition to the primary role and represent the state of the database prior to the failover. This can delay the resumption of production after failover.
- Various diagnostic features report availability group recovery queuing: When there is recovery queueing the AlwaysOn dashboard in SQL Server Management Studio may report an unhealthy availability group.
How to Check for Recovery (redo) Queueing
Recovery queue is a per-database measurement and can be checked using the AlwaysOn dashboard on the primary replica or using the sys.dm_hadr_database_replica_states DMV on the primary or secondary replica. There are Performance Monitor counters for checking for recovery queuing and recovery rate and those must be checked against the secondary replica.
Here’s one way you can actively monitor your availability group database recovery queue.
Query sys.dm_hadr_database_replica_states: The DMV sys.dm_hadr_database_replica_states reports a row for each availability group database and one column is the redo_queue_size which reports the recovery queue size in kilobytes. You can set up a query like the one below to monitor any trend in the redo queue size. The query is being run on the primary, it uses the predicate is_local=0 to report the data for the secondary replica, where redo_queue_size and redo_rate are relevant.
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.redo_queue_size, drs.redo_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc,
ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars
JOIN sys.dm_hadr_database_replica_cluster_states drcs
ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs
ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
WAITFOR DELAY '00:00:30'
ENDHow to Diagnose Recovery (Redo) Queueing
Once you have identified recovery queuing for a specific secondary replica availability group database, make a connection to the secondary replica and query sys.dm_exec_requests to review what the wait_type and wait_time is for recovery threads. Here is a query that can be executed in a loop. We are looking for a high frequency of one or more wait types and even wait times for those wait types. Here is a sample query that runs every second and reports the wait types and wait times for availability group ‘agdb’:
WHILE (1=1)
BEGIN
SELECT DB_NAME(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count
FROM sys.dm_exec_requests der
JOIN sys.dm_os_schedulers os
ON der.scheduler_id = os.scheduler_id
WHERE command IN('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id = DB_ID('agdb')
WAITFOR DELAY '00:00:05.000'
ENDSQL Server redo wait types
When a wait type is identified above, review the following article as a cross-reference for common wait types that cause recovery queuing and how to resolve.
Single Threaded Redo Could be the Cause
SQL Server introduced parallel recovery for secondary replica databases in SQL Server 2016. If you are experiencing recovery queuing while running SQL Server 2012 or SQL Server 2014, upgrading may improve redo performance in your production environment.
Single threaded redo can occur even on later, more advanced SQL Server versions where parallel recovery architecture is used, SQL Server 2016, SQL Server 2017 and SQL Server 2019. On these versions, a SQL Server instance can only use up to 100 threads for parallel redo. Depending on the number of processors and availability group databases, as parallel redo threads are allocated and the number approaches 100 total threads, some databases in the availability group are assigned a single redo thread.
To determine if your availability group database is using parallel recovery or not, connect to the secondary and use this query to determine the number of rows (threads) that are applying recovery for the availability group database, in the example below database ‘agdb.’ If it is a single thread, like its command is ‘DB STARTUP’, the recovery workload may benefit from parallel recovery.
SELECT DB_NAME(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count
FROM sys.dm_exec_requests der
JOIN sys.dm_os_schedulers os
ON der.scheduler_id = os.scheduler_id
WHERE command IN ('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id = DB_ID('agdb')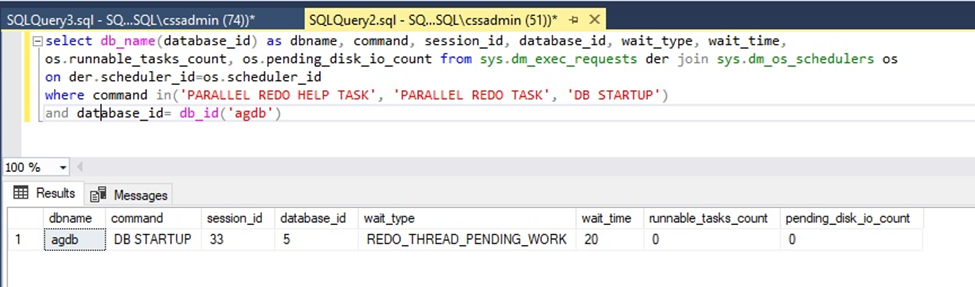
If you have confirmed your database is using single threaded redo, review the algorithm described above to determine if SQL Server is exceeding the number of 100 worker threads dedicated for parallel recovery, this may be the reason this database is only using a single thread for recovery. SQL Server 2022 now implements a new parallel recovery algorithm so that worker threads are assigned for parallel recovery based on workload, which eliminates the chances of a busy database remaining in single threaded recovery. For more information see Thread Usage by Availability Groups.
Conclusion
In conclusion, managing SQL Server’s Availability Groups is key for keeping databases reliable and quickly recoverable. Understanding how data is synced and the role of the ‘redo’ process is crucial for keeping data consistent across all copies. By using special monitoring tools and queries, database managers can keep a close watch on system performance and quickly fix any issues. This careful management helps ensure that databases can handle high demands with minimal disruptions.
Further Reading:
SQL Server 2022: Improving Database Performance with Enhanced Parallel Redo – SQL Table Talk